-
Attention Is All You NeedNAVER AI TECH 2023. 3. 28. 15:58
나동빈님께서 Transformer에 대해서 잘 설명해주셨다. 동영상, 실습 코드, ppt 파일까지 제공하고 있다.
https://github.com/ndb796/Deep-Learning-Paper-Review-and-Practice
GitHub - ndb796/Deep-Learning-Paper-Review-and-Practice: 꼼꼼한 딥러닝 논문 리뷰와 코드 실습
꼼꼼한 딥러닝 논문 리뷰와 코드 실습. Contribute to ndb796/Deep-Learning-Paper-Review-and-Practice development by creating an account on GitHub.
github.com
오늘(3/28) 피어 세션에서 다루었던 내용을 정리해보겠다.
논문 Attention Is All You Need의 3.1 Encoder and Decoder Stacks에서 "We employ a residual connection around each of the two sub-layers, followed by layer normalization."라는 문장이 나온다. 왜 Batch Normalization이 아닌 Layer Normalization을 사용했을까?
먼저 정규화(Normalization)가 무엇인지, 왜 필요한지부터 알아보겠다. 정규화는 입력 값의 범위와 단위를 맞춰주기 위해 사용한다. 가령 어떤 입력 데이터셋의 키의 범위는 145-195cm이고 몸무게 범위는 40-100kg이라면 서로 다른 범위와 단위를 가지게 되며 이는 머신러닝 알고리즘에서 문제가 될 수 있다. 따라서 feature scaling을 통해 범위와 단위를 통일시켜줄 필요가 있다. 대표적인 feature scaling 방법으로는 정규화(normalization)와 표준화(standardization)가 있다. 정규화와 표준화의 수식은 다음과 같다.
정규화
$x = \frac{x - x_{min}}{x_{max}-x_{min}}$
표준화
$z = \frac{x - \mu}{\sigma}$
그렇다면 정규화와 표준화 중 어떤 방법이 더 좋을까? 다음 글을 참고하자. 해당 글에 따르면 데이터 분포를 모를 때, 혹은 데이터 분포가 가우시안 분포가 아닐 때 정규화를 사용하는 것이 유용하다고 한다. 쓰던 글이 날라갔다........ 또 다른 글에서는 주성분 분석의 경우에는 표준화가 이미지 처리에서는 정규화가 유리하다고 한다. 실제 적용에서는 정규화라는 단어가 표준화를 포함한다고 하니 이어지는 글에서는 정규화와 표준화를 구분 짓지 않겠다. 쓰던 글이 날라가서 출처 두 개를 잃어버렸습니다.......
정규화를 적용해야 하는 대상에 따라서 Batch Normalization, Layer Normalization, Group Normalization 등의 방법이 나올 수 있다. 전통적으로 CNN의 경우에는 Batch에 대해서 RNN의 경우에는 Layer에 대해서 정규화를 적용해왔다. 먼저 Batch Normalization과 Layer Normalization이 어떻게 다른지 그림을 통해 파악하자.
(아래 내용은 Bala Priya C의 Article을 참고하여 작성하였다.)

https://www.pinecone.io/learn/batch-layer-normalization/ Batch Normalization은 mini-batch에 대해 각 feature에 독립적으로 정규화를 적용함을 확인할 수 있다.

https://www.pinecone.io/learn/batch-layer-normalization/ Layer Normalization은 features에 대해 각 sample에 독립적으로 정규화를 적용함을 확인할 수 있다.
Batch Normalization은 다음과 같은 문제점을 가진다. 첫째, batch size가 작을 경우 각 batch의 평균과 표준편차는 실제 데이터 분포를 대표할만큼 정확하지 않다. 둘째, sequence models에서는 sentence lengths가 가변적이므로 batch normalization에서 활용하는 normalization constant가 서로 다르게 되고 이는 불안정한 학습을 야기한다. 따라서 sequence data를 활용하는 RNN, LSTM, Transformer models의 경우 Layer Normalization을 default 값으로 사용하게 된다.
한편, BN(Batch Normalization)이 충분한 성능을 발휘하기 위해서는 batch size가 최소 32는 돼야 한다. 그러나 메모리 소모량이 높은 종류의 데이터를 학습하거나 매우 깊은 NN 모델을 학습해야 할 때 필연적으로 작은 batch size를 사용하게 된다. GN(Group Normalization)은 batch size로 인한 문제를 해결하기 위해 나온 방법론이다. 기본적으로 LN(Layer Normalization)을 일부 channels(=features)에 대해서만 적용한다고 보면 된다. 그룹의 숫자를 결정하는 G는 pre-defined hyperparameter이다.

https://towardsdatascience.com/what-is-group-normalization-45fe27307be7 다시 논문으로 돌아가서 LN을 적용하는 것과 $d_{model} = 512$와 관련이 있나는 질문이 있었다. 위위 사진(Normalization across features, independently for each sample)에서는 $x_1, x_2, x_3, x_4$에 대한 평균과 표준편차를 구해주었는데 논문에서는 $d_{model} = 512$이므로 $x_1, x_2, ..., x_{511}, x_{512}$에 대해서 평균과 표준편차를 구하면 될 것이다. 아마도
마지막으로 마스킹에 대한 질문이 있었다. Transformer에서는 세 번의 마스킹이 필요하다. 다음 내용은 딥 러닝을 이용한 자연어 처리 입문에서 가져왔다.
- 인코더의 셀프 어텐션 : 패딩 마스크를 전달
- 디코더의 첫번째 서브층인 마스크드 셀프 어텐션 : 룩-어헤드 마스크를 전달 (패딩 마스크도 전달)
- 디코더의 두번째 서브층인 인코더-디코더 어텐션 : 패딩 마스크를 전달
먼저, 패딩 마스크이다. <pad>의 경우 필요 없는 부분이므로 제거해줘야 한다.
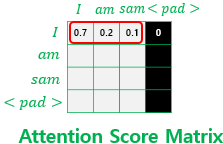
패딩 마스크 두 번째는 룩-어헤드 마스크이다. 앞에 있는 단어가 뒤에 있는 단어를 엿보는 것(cheating)을 막아야 한다.

룩-어헤드 마스크 마스킹 해야 하는 부분은 1, 나머지 부분은 0으로 구성된 행렬 mask가 주어졌다고 가정해보자.
이후, 아래 연산을 거쳤다고 가정해보자.
# 스케일드 닷 프로덕트 어텐션 함수를 다시 복습해봅시다. def scaled_dot_product_attention(query, key, value, mask): ... 중략 ... logits += (mask * -1e9) # 어텐션 스코어 행렬인 logits에 mask*-1e9 값을 더해주고 있다. ... 중략 ...logits에 softmax를 적용하면 매우 작은 음수는 0에 수렴하게 된다. $\rightarrow$ 마스킹에 성공했다!!
다 적고보니 시간이 훌쩍 갔다. 중간에 글만 안 날라갔어도. 티스토리는 버전 관리 기능을 제공하라.
'NAVER AI TECH' 카테고리의 다른 글
8주차 회고록 (AI 서비스 개발 기초) (0) 2023.04.28 7주차 회고록 (Level 1 Project 종료) (0) 2023.04.22 Word Embedding (4주차) (0) 2023.03.27 Intro to NLP (4주차) (0) 2023.03.27 3주차 회고록 (DL Basic & Data Visualization & Git) (0) 2023.03.24