-
MiniGPT-v2: Large Language Model As a Unified Interface for Vision-Language Multi-task Learning논문 2023. 12. 15. 23:03
https://arxiv.org/abs/2310.09478
MiniGPT-v2: large language model as a unified interface for vision-language multi-task learning
Large language models have shown their remarkable capabilities as a general interface for various language-related applications. Motivated by this, we target to build a unified interface for completing many vision-language tasks including image description
arxiv.org
Introduction
최근 비전 관련 연구에서 멀티 모달 초거대 모델(Multi-modal Large Language Models)이 인기를 얻고 있다. 멀티 모달 LLM의 주요 특징은 멀티 모달 LLM이 LLM의 향상된 능력(논리적 추론, 상식, 강한 언어적 표현)을 이어받아 사용한다는 것이다. 멀티 모달 LLM은 비전-언어 영역에서 다양한 역할(image descriptions, generating code, localizing the visual objects in the image, performing multi-modal reasoning)을 수행할 수 있다는 사실이 밝혀졌으나, 서로 다른 과제의 내재적인 차이로 인해서 멀티-모달 지시에 따라 다양한 비전-언어 과제를 "함께" 수행할 수 있는 모델을 개발하는 데는 어려움이 따른다.
이 문제를 해결하기 위해서 본 연구진은 "task-oriented instruction training scheme"이라는 방법을 사용해 MiniGPT-v2를 구축했다. 해당 모델을 image/grounded captioning, vision question answering, visual grounding 영역에서 평가하였고, 본 모델이 SOTA 혹은 그에 근접한 성능을 보여주는 것을 확인했다.

Method
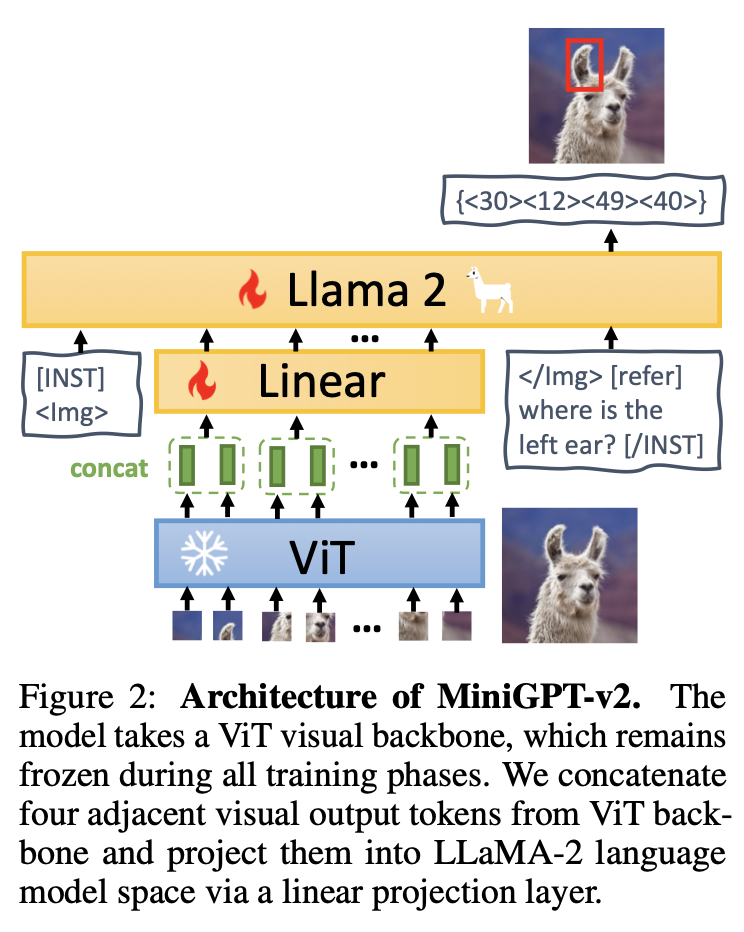
Visual Backbone
MiniGPT-v2는 중추 모델로 EVA를 사용한다. EVA는 ViT(Vision Transformer)모델이다. 훈련 중에는 중추 모델을 얼렸다. 해상도가 448x448인 이미지를 훈련에 사용했다.
Linear projection layer
고해상도 이미지의 모든 이미지 토큰을 LM에 한 번에 통과시키면 너무 긴 입력 데이터로 인해 훈련 및 추론 속도가 저하될 수 있다. 따라서, 임베딩 공간 내 4개의 인접한 시각 토큰을 이어붙인 후 LLM의 동일한 피쳐 공간에 있는 단일 임베딩에 투사했다.
Large language model
LM의 중추 모델로 LLaMA2-chat(7B)을 사용했다. LLaMA2의 언어 토큰에 기반하여 다양한 비전-언어 과제를 수행했다.
Multi-task Instruction Template
"빨간 옷을 입은 사람의 위치를 알려줘."라는 질문에 대해, 모델은 bounding box 형식으로 답변할 수도 있고, 자연어 형태로 답변할 수도 있다. 이런 모호함을 줄이기 위해서 본 연구진은 "task- specific tokens"라는 개념을 모델 훈련에 이용했다.
General input format
LLaMA-2 대화 템플릿은 일반적으로 다음과 같다. 여기서 [INST]는 사용자 역할을, [/INST]는 보조자(assistant) 역할을 뜻한다.
[INST] <Img> < ImageFeature> </Img> [Task Identifier] Instruction [/INST]
Task identifier tokens
[Task Identifier]에 6가지 서로 다른 과제를 위한 6개의 서로 다른 토큰을 사용하였다.

Spatial location representation
한편, 시각적 위치 표상이 필요한 과제에서는 범위 [0,100]에서의 “{< $X_{left}$ >< $Y_{top}$ >< $X_{right}$ >< $Y_{bottom}$ >}"을 사용하였다.
Multi-task Instruction Training
특정 과제 식별자 토큰을 입력 데이터로 활용하여 훈련하는 것이 기본 아이디어이다. 다음과 같은 3단계로 구성되어 있다. 1~3단계에서의 특정 데이터셋 활용 여부는 아래 테이블에서 확인할 수 있다.
Stage 1: Pretraining
모델이 넓은 비전-언어 지식을 갖게 하기 위해서 1) weakly-labeled 데이터셋과 2) fine-grained 데이터셋을 모두 훈련에 활용하였다. 모델이 더 넓은 지식을 가질 수 있도록 첫 단계에서는 weakly-labeled 데이터셋을 더 많이 샘플링하였다.
Stage 2: Multi-task training
MiniGPT-v2의 각 과제 수행 능력을 높이기 위해서, 이번에는 weakly-labeled 데이터셋은 배제하고 fine-grained 데이터셋만을 훈련에 활용하였다. 각 과제의 빈도에 맞게 데이터셋을 샘플링하였다.
Stage 3: Multi-modal instruction tuning
모델을 멀티 모달 지시 데이터셋에 맞추고 챗봇으로서의 대화 능력을 기르기 위해서, 이번 단계에서는 2단계에서의 데이터셋에 더해 지시 데이터셋을 훈련에 활용하였다. 2단계에서의 fine-grained 데이터셋은 덜 샘플링하고 새롭게 더해진 지시 데이터셋은 더 샘플링하였다.

## Flicker 30k ##
부족한 성능을 끌어올리기 위한 데이터셋 추가 과정이 흥미로웠다. 2단계까지 진행했을 때, MiniGPT-v2는 grounded image caption을 효과적으로 만들 수 있었으나, grounded image caption의 묘사가 짧고 적은 숫자의 시각적 물체밖에 다루지 않는다는 문제점을 갖고 있었다. 이는 훈련에 사용한 GRIT-20M 데이터셋에서 각 캡션이 제한된 숫자의 시각적 물체만 주요 특징으로 삼고 있었기 때문이다. 결과적으로 MiniGPT-v2는 더 많은 시각적 물체를 인식하도록 가르치는 멀티 모달 지시 조정 능력이 부족하게 되었다. 이 문제를 해결하기 위해서 캡션 내 엔터티에 대한 더 많은 맥락적 그라운딩을 제공하는 Flickr30k 데이터셋을 활용하였다. 1) Grounded image caption과 2) Object parsing and grounding 훈련을 위해서 Flickr30k 데이터셋 내 데이터를 적절히 선택 및 변형하였다.
## Mixing multi-task dataset ##
single-round 지시-답변 쌍으로 훈련 받은 모델은, multi-round 대화를 통한 다중 과제 수행에 약할 수밖에 없다. 이 문제를 해결하기 위해서, 서로 다른 과제의 데이터를 섞은 multi-round 대화 데이터셋을 만들었으며, 3단계 훈련 수행 시 활용하였다.
## Unnatural instruction ##
대규모의 비전-언어 훈련 후, LM의 대화 능력이 약화될 수 있다. 이 문제를 해결하기 위해서, 언어 데이터셋인 Unnatural Instruction을 3단계 훈련에 포함하였다.
Experiments
1) 선형 투사층에 대한 훈련과 2) LM 모델에 대한 파인튜닝을 LoRA를 통해 수행했다.
실험 결과는 아래 표를 통해 확인할 수 있다.

Ablation on task identifier
task identifier를 활용했을 때 모델의 성능이 더 높았다.

Hallucination
타 유사 모델에 비해 image description generation 과제에서의 hallucination이 적었다. 특히, 프롬프트를 변형하여 제공함으로 hallucination을 더 낮출 수 있었다. 본 연구진은 더 질 좋은 이미지-텍스트 데이터를 훈련에 활용하고, 더 강력한 중추 비전 모델 혹은 LM 모델을 활용함으로 hallucination을 더욱 낮출 수 있다고 본다.

Qualitative Results
아래 그림을 통해 MiniGPT-v2의 활용 예시를 볼 수 있다.

바로 직전에 다루었던 VisionLLM에 비해서 데이터셋의 활용에 대한 고민의 흔적이 더 돋보였다. 물론 MiniGPT와 모델 구성이 유사하여 데이터셋 설명에 비중을 높였을 수도 있다. ViT --> Linear Layer --> LM으로 이어지는 모델 구성은 전혀 복잡하지 않았다. task identifier token을 추가하는 것도 생각해볼법한 개념이다. 단순한 아이디어임에도 불구하고 1-3단계 모델 훈련을 통해서 높은 성능을 이끌어냈다는 점이 대단하게 보인다. 정말 다양한 종류의 데이터셋을 사용했는데, 이에 상응하는 한국어로 구성된 데이터셋이 존재하는지 궁금했다. 한국어 기반 데이터셋으로 동일한 모델을 제작한다면 그 모델의 성능은 어느 정도일까?
'논문' 카테고리의 다른 글