-
seq2seqNAVER AI TECH 2023. 4. 3. 11:37
seq2seq
Structure
기본적인 seq2seq model은 다음과 같다.

attention(alignment)을 활용한 seq2seq model은 다음과 같다.

Attention Calculation
attention을 계산하는 다양한 방법을 소개한다.

Strength
- Attention significantly improves NMT(Neural Machine Translation) performance
• It is useful to allow the decoder to focus on particular parts of the source - Attention solves the bottleneck problem
• 병목(영어: bottleneck) 현상은 전체 시스템의 성능이나 용량이 하나의 구성 요소로 인해 제한을 받는 현상을 말한다.
• Attention allows the decoder to look directly at source; bypass the bottleneck - Attention helps with vanishing gradient problem
• Provides a shortcut to far-away states - Attention provides some interpretability
• By inspecting attention distribution, we can see what the decoder was focusing on
• The network just learned alignment by itself
Practice
(5강-실습) Seq2Seq 구현_조민우_T5200
(6강-실습) Seq2Seq with Attention 구현_조민우_T5200
Beam Search
Idea
greedy search(k=1)와 exhaustive search(k = len(V))의 절충안
* greedy search의 경우 앞선 output decision을 되돌릴 수 없다.* exhaustive search의 경우 복잡도가 O($V^t$)이므로 실제 적용이 거의 불가능하다.
$\rightarrow$ beam search: on each time step of the decoder, we keep track of the 𝑘 most probable partial translations.
Calculation
score가 가장 높은 경우의 수를 선택하여 출력한다.
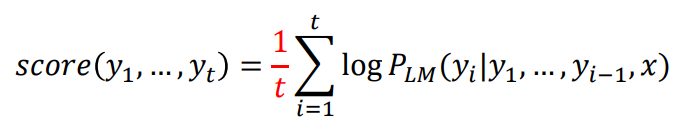
BLEU
predicted_output과 ground_truth와의 일치도를 계산하는 방법이다. 기하평균을 활용하였다.
Calculation

Strength
정확히 예측된 단어의 숫자와 단어 사이의 관계(위치)를 모두 고려하였다.
'NAVER AI TECH' 카테고리의 다른 글
7주차 회고록 (Level 1 Project 종료) (0) 2023.04.22 Transformer (0) 2023.04.05 RNN, LSTM, and GRU (0) 2023.03.29 Attention Is All You Need (0) 2023.03.28 실습 (3주 1일차) (0) 2023.03.27 - Attention significantly improves NMT(Neural Machine Translation) performance